Distillation: Size Matters in AI

Artificial Intelligence models are getting bigger, better, and… bulkier. In the race for state-of-the-art performance, we’ve built behemoth models that deliver jaw-dropping accuracy but demand a king’s ransom in computational resources. Knowledge distillation, is a technique that lets you bottle up the smarts of a large, cumbersome model and pour them into a lean, efficient one.
In this guide, we’ll explore everything about knowledge distillation. Whether you’re an ML practitioner or an AI enthusiast, this article will break it all down, step by step.
What is Knowledge Distillation?
At its core, knowledge distillation is a process where a large, pre-trained model (called the teacher) teaches a smaller, more efficient model (the student) to replicate its performance. The student doesn’t just learn from the ground truth labels (like a standard model) — it also absorbs the nuanced “knowledge” of the teacher model, encoded in its probability distributions.
Why is this important?
- Model Compression: Smaller models are cheaper, faster, and easier to deploy on edge devices like phones and IoT devices.
- Efficiency: A lightweight student model can make predictions much faster than a large teacher model without significant performance loss.
- Scalability: Training and deploying smaller models make AI more accessible and environmentally sustainable.
1. Intuition Behind Knowledge Distillation
Large models don’t just learn what’s right or wrong — they also learn how right or how wrong each possibility is. This “richness” is captured in their probability distributions over classes, known as soft targets. Let’s break this down:
Hard Targets vs. Soft Targets
- Hard Targets: These are ground-truth labels — binary and unambiguous. For example, in a classification task, an image of a dog might have the label “Dog” (Class A).
- Soft Targets: Instead of assigning one class as “100% correct,” the teacher model assigns probabilities to all classes. For instance:
- Dog: 70%
- Wolf: 20%
- Cat: 10%
The probabilities in soft targets encode information about inter-class relationships. The teacher implicitly tells the student, “This looks mostly like a dog, but it also has some wolf-like features.”
By mimicking these soft targets, the student model learns to generalize better, often outperforming a model trained solely on hard targets.
2. Mathematical Foundations
Let’s dissect the key mathematical concepts.
Softmax and Temperature Scaling
The softmax function converts raw logits (unnormalized scores) into probabilities:

In knowledge distillation, we introduce a temperature parameter (T) to smoothen the probabilities:

High T: Produces a smoother probability distribution (easier for the student to learn).
Low T: Makes probabilities more “peaky.”
The teacher uses a high temperature to produce soft targets for the student.
KL Divergence: Measuring Similarity Between Distributions
To train the student, we compare the teacher’s and student’s probability distributions using Kullback-Leibler (KL) divergence, defined as:

Here:
- P: Teacher’s probability distribution (soft targets).
- Q: Student’s probability distribution.
KL divergence measures how much the student’s predictions deviate from the teacher’s. Minimizing this divergence forces the student to mimic the teacher.
The Total Loss Function
The total loss function combines:
- Distillation Loss (soft targets): Guides the student to learn from the teacher.
- Standard Cross-Entropy Loss (hard targets): Ensures the student performs well on the ground truth labels.
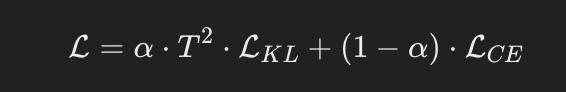
- α: Balances the weight between soft and hard targets.
- T²: Accounts for the scaled logits when using temperature.
3. Why Does Knowledge Distillation Work?
Rich Information from Soft Targets
Soft targets encode inter-class relationships. For example, if the teacher assigns:
- Dog: 0.6
- Wolf: 0.3
- Cat: 0.1
The student learns that the image resembles a dog but shares features with a wolf — a nuance that hard labels like “Dog” would miss.
Smoother Optimization
Soft targets provide gradients that are less noisy and more informative, helping the student converge faster and generalize better.
Reduced Overfitting
The teacher acts as a “regularizer,” preventing the student from overfitting to noisy or incorrect ground-truth labels.
4. Practical Implementation in PyTorch
Let’s implement knowledge distillation with PyTorch using an MNIST dataset.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader# Define teacher and student models
class TeacherModel(nn.Module):
def __init__(self):
super(TeacherModel, self).__init__()
self.network = nn.Sequential(
nn.Linear(784, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
def forward(self, x):
return self.network(x)class StudentModel(nn.Module):
def __init__(self):
super(StudentModel, self).__init__()
self.network = nn.Sequential(
nn.Linear(784, 128), # Smaller model
nn.ReLU(),
nn.Linear(128, 10)
)
def forward(self, x):
return self.network(x)# Load dataset
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)# Initialize models
teacher = TeacherModel()
student = StudentModel()# Loss functions and optimizer
temperature = 5.0
alpha = 0.7
criterion_ce = nn.CrossEntropyLoss()
criterion_kl = nn.KLDivLoss(reduction='batchmean')optimizer = optim.Adam(student.parameters(), lr=0.001)# Training loop
def train_distillation(teacher, student, train_loader, optimizer, criterion_ce, criterion_kl, alpha, temperature):
teacher.eval()
student.train()
for epoch in range(5):
total_loss = 0
for images, labels in train_loader:
images = images.view(-1, 28*28)
with torch.no_grad():
teacher_logits = teacher(images)
student_logits = student(images)
# Compute soft targets
teacher_probs = torch.softmax(teacher_logits / temperature, dim=1)
student_probs = torch.log_softmax(student_logits / temperature, dim=1)
# KL divergence loss
loss_kl = criterion_kl(student_probs, teacher_probs) * (temperature ** 2)
# Cross-entropy loss
loss_ce = criterion_ce(student_logits, labels)
# Total loss
loss = alpha * loss_kl + (1 - alpha) * loss_ce
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {total_loss / len(train_loader)}")# Train the student model
train_distillation(teacher, student, train_loader, optimizer, criterion_ce, criterion_kl, alpha, temperature)
5. Applications of Knowledge Distillation
- Model Compression: Use small models for deployment on resource-constrained devices.
- Ensemble Models: Train a student to aggregate the knowledge of multiple teachers.
- Domain Adaptation: Transfer knowledge from a teacher trained on a large dataset to a student in a different domain.
- Multi-task Learning: Distill knowledge from a multi-task teacher to a student specializing in one task.
Knowledge distillation is more than just a clever hack for model compression — it’s a cornerstone of efficient AI. By distilling the wisdom of a large teacher model into a smaller student, we achieve the best of both worlds: high performance and low resource consumption. As AI continues to scale, knowledge distillation will be a key tool in making models accessible, scalable, and sustainable.
So go ahead, build your AI models smarter, not harder! 🚀
